Machine learning (ML) has transformed industries across the globe, enabling systems to analyze data, make decisions, and solve complex problems with little human intervention. One of the most widely used approaches within ML is supervised learning, where algorithms learn from labeled data to make predictions or classifications. In this blog, we’ll dive deep into the world of supervised machine learning (SML), explore its types, understand how it works, and provide real-life examples to contextualize its applications.
What is Supervised Machine Learning?
Supervised machine learning refers to a class of algorithms that learn from labeled training data. In this context, “labeled” means that each training example consists of input-output pairs, where the output is the correct result or classification that the algorithm should predict.
The goal of supervised learning is to create a model that can generalize from this labeled data to unseen data, making accurate predictions when presented with new, unlabeled instances. The supervised learning process typically follows these steps:
- Data Collection: Gather labeled data relevant to the problem you’re trying to solve.
- Data Preprocessing: Clean and format the data so it can be fed into a machine learning model.
- Training the Model: Feed the training data into the model so it can learn patterns between inputs and outputs.
- Evaluation and Testing: Once the model is trained, evaluate its performance on unseen test data to measure its accuracy.
- Prediction: Deploy the trained model to make predictions on new, real-world data.
Types of Supervised Machine Learning
Supervised learning is generally divided into two primary types based on the nature of the target output:
- Regression
- Classification
Both approaches involve using labeled datasets, but they differ in the type of output they generate.
1. Regression
In regression problems, the goal is to predict a continuous numerical value based on the input data. The output variable is typically a real number, such as temperature, price, or age. The algorithm tries to establish a mathematical relationship between the input variables (features) and the output variable.
Real-Life Example: House Price Prediction
Imagine you’re tasked with predicting the price of a house based on various features such as square footage, number of bedrooms, location, and proximity to amenities. The data you have includes these features along with the actual sale prices of houses (the labeled output). You can use a regression model to learn from this data and predict prices for new, unseen houses.
Popular Algorithms for Regression:
- Linear Regression: A simple algorithm that assumes a linear relationship between input and output variables.
- Polynomial Regression: This extends linear regression by fitting a polynomial relationship.
- Decision Trees and Random Forests: Tree-based models that can capture more complex relationships by splitting the data into smaller groups.
- Support Vector Regression (SVR): A version of support vector machines applied to regression problems.
Formula for Linear Regression:

2. Classification
In classification problems, the goal is to predict a categorical label or discrete value. The output is one of a predefined set of categories or classes. For example, determining whether an email is spam or not (binary classification) or classifying images of animals (multi-class classification) are classic use cases.
Real-Life Example: Email Spam Detection
A common use of supervised learning is in filtering spam emails. Given a labeled dataset of emails, some marked as “spam” and others as “not spam,” a classification model can learn to differentiate between the two. Features such as email content, subject lines, sender information, and frequency of specific keywords can all help the model predict whether a new email is likely spam.
Popular Algorithms for Classification:
- Logistic Regression: Despite its name, logistic regression is used for binary classification, modeling the probability of an outcome that can take two values.
- Decision Trees: Trees classify instances by asking a sequence of questions that divide the dataset into smaller and more homogeneous subsets.
- Random Forests: An ensemble method that builds multiple decision trees and aggregates their results for more accurate predictions.
- Support Vector Machines (SVM): A powerful classifier that finds the optimal hyperplane to separate classes.
- k-Nearest Neighbors (k-NN): A simple, instance-based method that classifies new data points based on their proximity to existing labeled points.
- Neural Networks: Often used for more complex classification tasks like image or speech recognition.
Logistic Regression Equation:

How Supervised Learning Works: The Learning Process
Supervised learning works by presenting the machine with examples of input-output pairs and enabling it to “learn” the relationship between these inputs and outputs. Let’s break down the process:
1. Labeled Dataset
A labeled dataset is one in which each input is paired with the corresponding correct output. In a dataset for house price prediction, for instance, every row would include data about a house (square footage, number of bedrooms, etc.) and the actual price it sold for (the label).
2. Training the Model
Once the dataset is collected and preprocessed, it is split into two subsets:
- Training Data: Used to train the model by allowing the algorithm to find patterns in the data.
- Testing Data: Held out to evaluate the model’s performance on new, unseen data.
The algorithm tries to minimize the error in its predictions by adjusting its parameters during the training phase.
3. Loss Function
The model measures its prediction errors using a loss function, which quantifies how far the predicted values are from the actual values. The model iteratively adjusts its parameters (e.g., weights in linear regression) to reduce the loss.
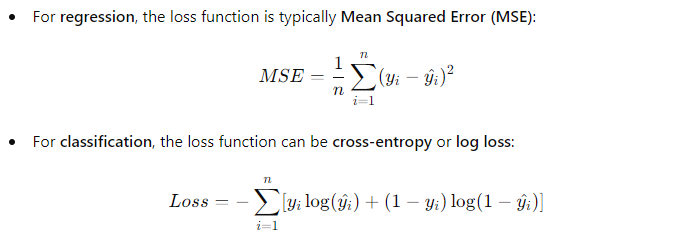
4. Model Evaluation
After the model has been trained, it is tested using the testing dataset. Common evaluation metrics include:
- Accuracy: Proportion of correctly classified instances.
- Precision and Recall: Measures of classification performance, especially in imbalanced datasets.
- Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE): Used in regression tasks to measure the difference between predicted and actual values.
Real-Life Applications of Supervised Learning
Supervised learning is incredibly versatile and powers many everyday technologies. Here are some common real-world applications:
1. Healthcare: Disease Diagnosis
In healthcare, supervised learning models are used to predict diseases from patient data. For example, in detecting breast cancer, algorithms can analyze patient history, symptoms, and medical images to predict whether a tumor is malignant or benign. Models trained on labeled data (cases with known diagnoses) can help assist doctors in making faster, more accurate diagnoses.
2. Finance: Fraud Detection
In financial services, supervised learning models are employed to detect fraudulent transactions. By analyzing labeled datasets containing both fraudulent and legitimate transactions, models can learn patterns that distinguish between the two and flag suspicious activity in real-time.
3. Customer Support: Sentiment Analysis
Many businesses leverage sentiment analysis to determine whether customer feedback (from reviews, social media posts, etc.) is positive or negative. This involves training a classification model on labeled data containing customer reviews and their corresponding sentiment. The model can then classify new feedback to gauge customer satisfaction.
4. Marketing: Customer Segmentation
Supervised learning helps marketers segment customers into different categories based on their purchasing behaviors, preferences, and demographics. This enables more targeted marketing efforts, personalized offers, and improved customer experience. Models trained on labeled customer data can predict which segment a new customer belongs to and help inform strategic decisions.
5. Natural Language Processing: Text Classification
In NLP, supervised learning is applied in various tasks such as spam detection, language translation, and text classification. For example, a model trained on labeled movie reviews (positive or negative) can classify new reviews based on their content. Another example is language translation, where models are trained on sentence pairs (source language and
target language) to translate new sentences accurately.
Challenges in Supervised Learning
While supervised learning is a powerful tool, it comes with several challenges:
1. Data Labeling
For supervised learning to work, large amounts of labeled data are required. Labeling data can be time-consuming, expensive, and prone to errors. In many cases, obtaining labeled data is the bottleneck in implementing supervised learning systems.
2. Overfitting
Overfitting occurs when the model learns the noise in the training data instead of the true underlying patterns. This happens when the model is too complex relative to the amount of training data. Overfitting leads to poor generalization to new, unseen data.
3. Class Imbalance
In many real-world datasets, the classes may not be equally represented. For example, in fraud detection, fraudulent transactions are much rarer than legitimate ones. This imbalance can skew the model’s predictions, making it less sensitive to minority classes.
4. Model Interpretability
Some supervised learning algorithms, like deep neural networks, are difficult to interpret. In industries such as healthcare or finance, understanding the decision-making process of a model is crucial for trust and regulatory reasons.
Conclusion
Supervised machine learning is an indispensable approach for tasks that require predictive modeling based on labeled data. Whether it’s predicting house prices, detecting fraud, or diagnosing diseases, supervised learning algorithms have far-reaching implications across industries. Understanding the distinction between regression and classification tasks, knowing which algorithms to apply, and recognizing potential pitfalls are all essential for leveraging the power of supervised learning in real-world applications.
As data continues to grow in volume and variety, supervised learning models will only become more sophisticated, driving innovation and creating new opportunities for data-driven decision-making. By mastering the fundamentals of supervised learning, businesses and individuals alike can unlock the full potential of their data and build solutions that are accurate, scalable, and transformative.