The Tanh function scales inputs between -1 and 1, and it’s often used in hidden layers of a neural network.
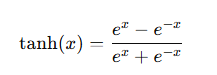
- Advantages: Zero-centered outputs help in faster convergence.
- Drawbacks: Like the sigmoid, it suffers from the vanishing gradient problem.
To address the dead neuron problem, the Leaky ReLU introduces a small slope for negative inputs:
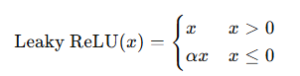
- Advantages: Avoids dead neurons by allowing a small gradient when x≤0x \leq 0.
- Drawbacks: Higher computational cost than ReLU.
Softmax is commonly used in the output layer for multi-class classification tasks. It converts the output into a probability distribution over classes.
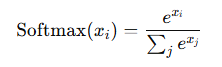
- Advantages: Ideal for multi-class problems, ensures outputs add up to 1.
- Drawbacks: Can lead to saturation, especially when class differences are stark.