Understanding Overfitting and Avoiding It in Deep Learning

In the realm of deep learning, building highly accurate models is often a priority. However, there’s a common pitfall that developers and researchers frequently encounter: overfitting. In this blog, we will explore what overfitting is, why it happens, and the best strategies to avoid it.
What is Overfitting?
Overfitting occurs when a model learns not only the underlying pattern in the training data but also the noise and outliers. This means the model performs well on the training data but fails to generalize to unseen data, leading to poor performance on validation or test datasets.
In simpler terms, the model becomes “too good” at capturing the details of the training data, making it unable to perform well on new, unfamiliar data.
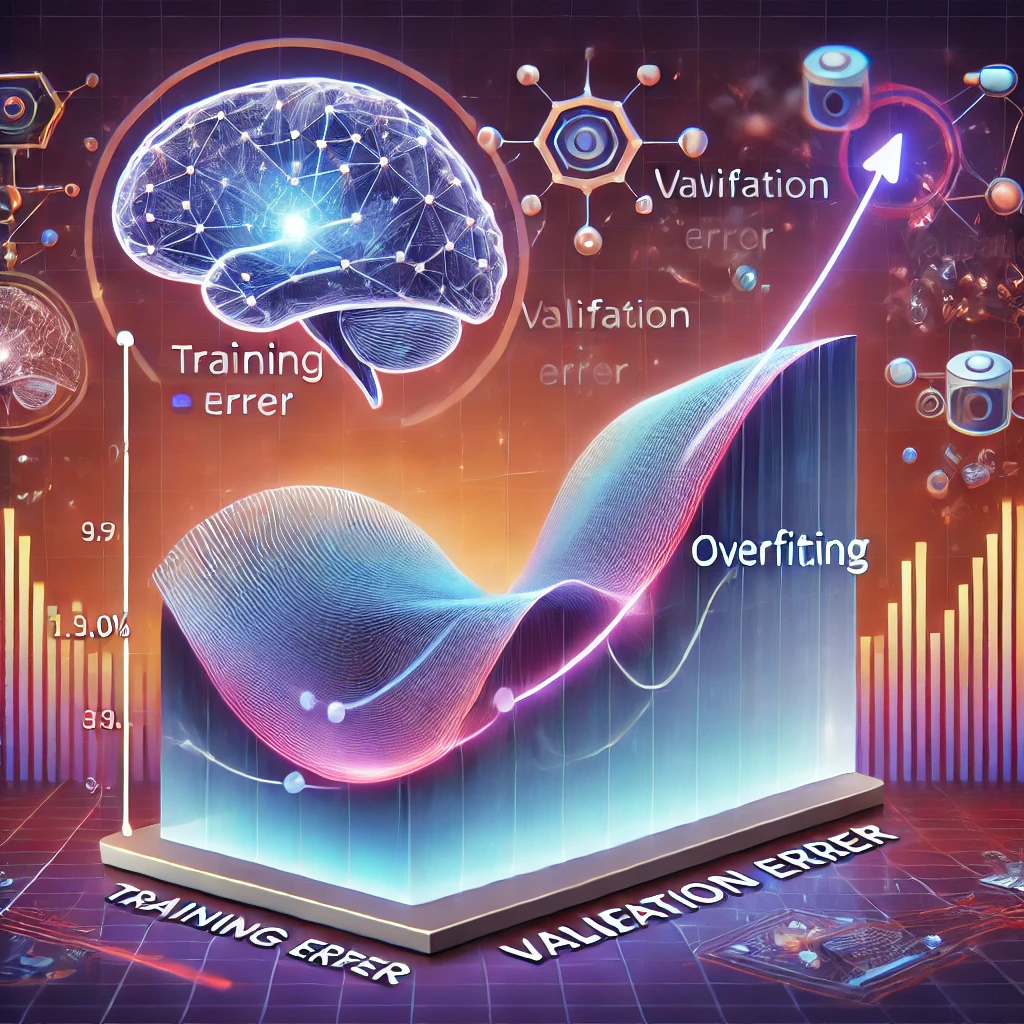
Graphical Representation of Overfitting:
In the graph below, we see how the training error decreases as the model becomes more complex, but the validation error starts increasing. This is a clear indicator of overfitting. Initially, both the training and validation errors decrease, but at some point, the validation error shoots up while the training error keeps decreasing. This gap marks the point of overfitting.
Causes of Overfitting
- Complex Models: Deep neural networks with many parameters can easily capture patterns in the data, but they might also learn noise and anomalies.
- Small Datasets: When training on small datasets, models tend to memorize the training data instead of learning generalized patterns.
- Lack of Regularization: Regularization techniques prevent models from becoming too complex. Without them, models are more prone to overfitting.
How to Identify Overfitting
To identify if your model is overfitting, look for the following signs:
- High training accuracy but low validation accuracy.
- Increasing validation loss after several epochs while training loss continues to decrease.
How to Avoid Overfitting
-
Use More Data: The most straightforward solution is to gather more data, which helps the model generalize better. However, acquiring more data isn’t always feasible.
-
Data Augmentation: If getting more data is difficult, you can augment your existing data. For example, for image data, you can apply transformations like rotations, flips, and crops to create new examples.
-
Early Stopping: Early stopping prevents the model from training too long and overfitting. By monitoring validation loss, you can halt training when the loss starts increasing, indicating overfitting.
-
Regularization Techniques: Regularization methods, such as L1 (Lasso) and L2 (Ridge), add penalties to the model’s loss function to discourage overly complex models.
-
Dropout: Dropout is a technique where random neurons are “dropped” during training, forcing the network to not rely on any one feature too much. This prevents overfitting and enhances generalization.
-
Cross-Validation: Using techniques like k-fold cross-validation ensures the model is evaluated on different portions of the data, reducing overfitting chances.
-
Simplify the Model: Sometimes, the model’s architecture might be unnecessarily complex for the task at hand. Reducing the number of layers or neurons can make the model less prone to overfitting.
-
Use Transfer Learning: Transfer learning allows you to use pre-trained models that have already learned to generalize on larger datasets. This can improve performance, especially on smaller datasets.
Conclusion
Overfitting is a common challenge in deep learning, but understanding its causes and implementing the right strategies can significantly reduce its impact. By using techniques like regularization, data augmentation, and early stopping, you can train models that perform well not only on training data but also on unseen data. Keeping the balance between underfitting and overfitting is crucial for building robust deep learning models.
Post: Understanding Overfitting and Avoiding It in Deep Learning
Overfitting occurs when a deep learning model performs exceptionally well on training data but poorly on unseen or validation data. This happens because the model learns not only the underlying patterns but also the noise and anomalies in the training data, making it less capable of generalizing to new data.
Overfitting can be detected by monitoring the performance metrics during training. If the training accuracy continues to improve while the validation accuracy stagnates or decreases, this indicates overfitting. Similarly, if the validation loss increases after a certain point, even though the training loss keeps decreasing, it suggests that the model is overfitting.
Overfitting typically occurs due to:
- Model Complexity: Large models with too many parameters can memorize training data, including noise.
- Small Dataset: When training data is limited, the model might learn specific details and noise rather than general patterns.
- Insufficient Regularization: Lack of techniques like dropout or regularization can allow models to become too complex, leading to overfitting.
To prevent overfitting, you can:
- Use more training data or employ data augmentation to artificially increase dataset size.
- Implement early stopping to halt training when validation loss starts to increase.
- Apply regularization techniques (e.g., L2 or L1 regularization) to discourage overly complex models.
- Use dropout to randomly deactivate neurons during training, forcing the model to generalize better.
- Simplify the model by reducing the number of layers or parameters.
Yes, overfitting is generally undesirable because it means the model fails to generalize well to new, unseen data. A model that overfits will likely perform poorly in real-world scenarios. However, in some cases, slight overfitting may be tolerated if training and validation datasets are very similar, but this is rare and not recommended for robust models.